Uploading BOM Data with PCB Data
There are 2 methods (Method 1 & 2) either via the Eurocircuits website Home Page or from within the PCB Calculator.
Method 1 – From the Eurocircuits Home Page
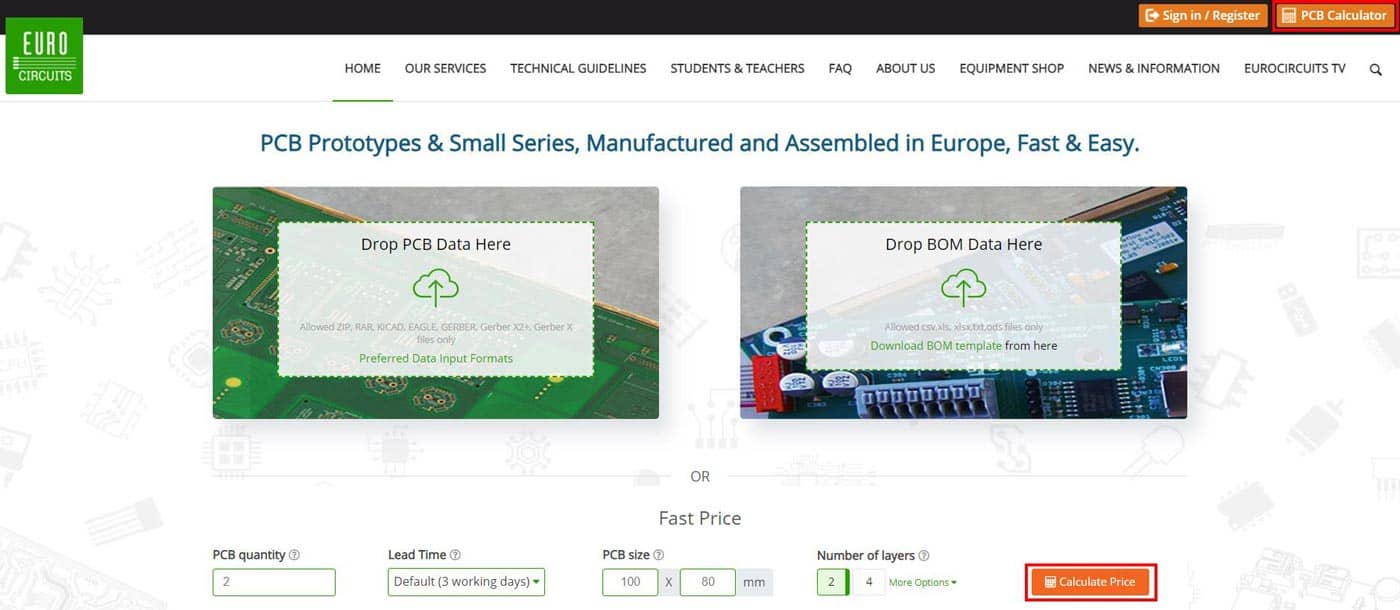
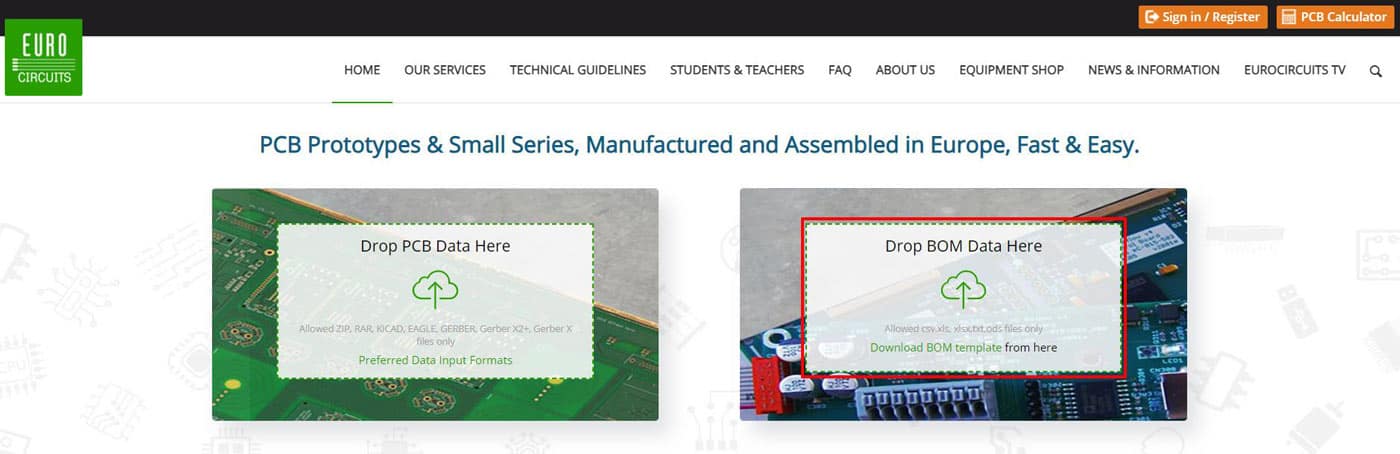
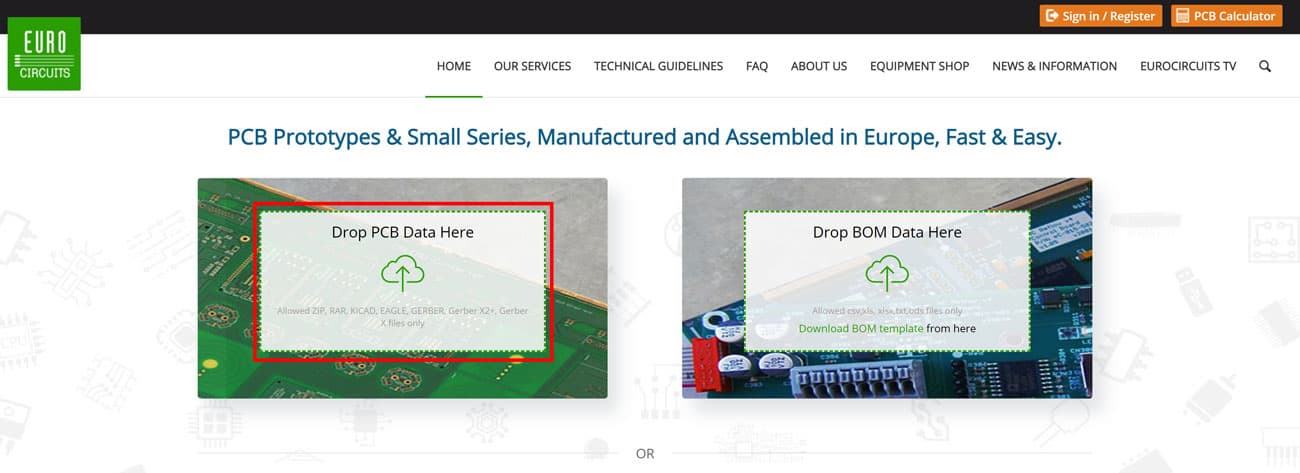
On the Home page simple Drag & Drop your PCB Data file(s) into the “Drop PCB Data Here” box or left mouse click in the box to browse for the PCB Data file(s) to be uploaded.
This will then open a pop window where you click on the “Upload BOM data” orange button (bottom right).
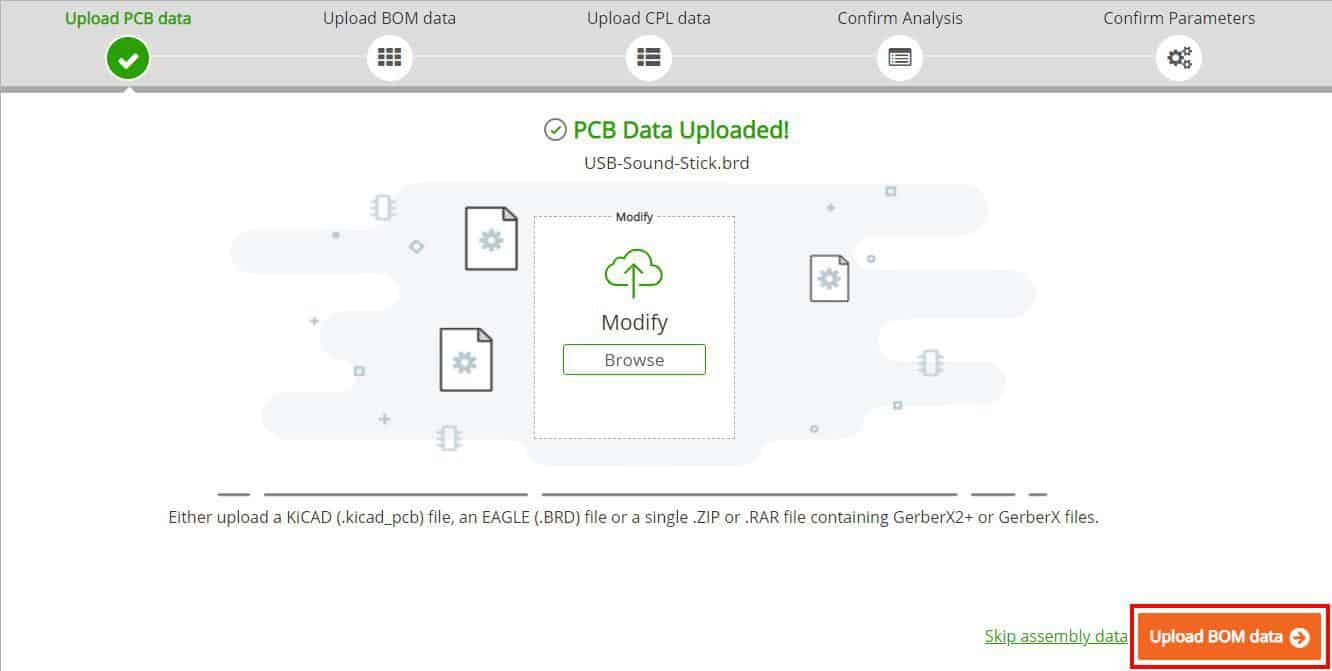
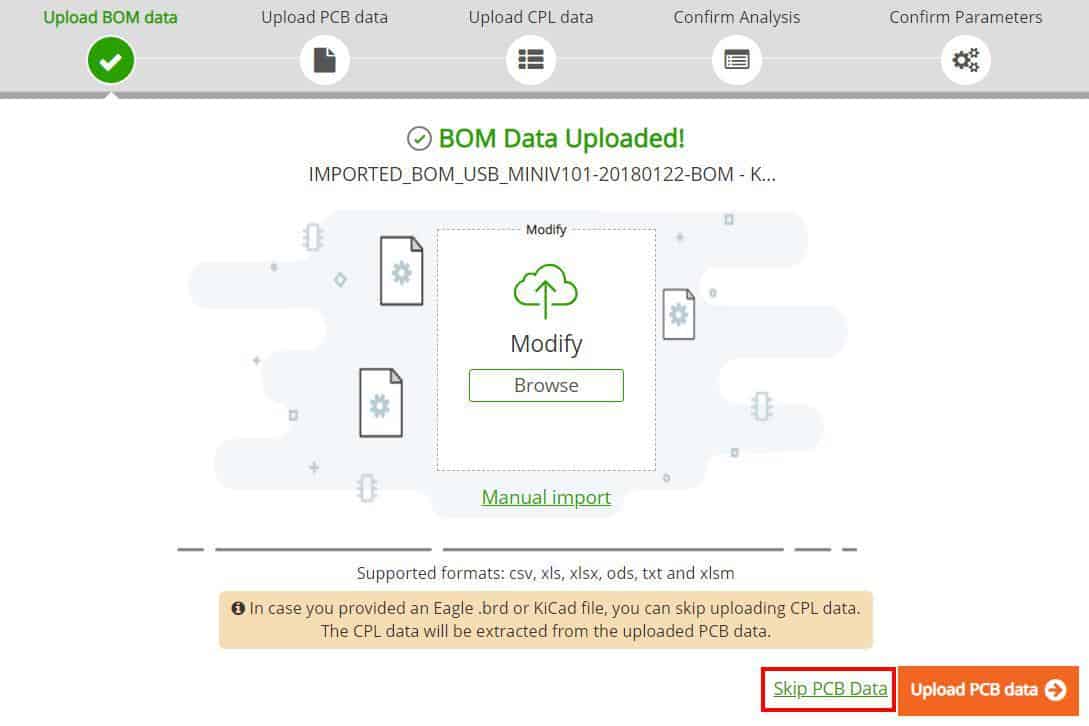
The new window will allow you to Drag & Drop your BOM Data file or browse and select the file.
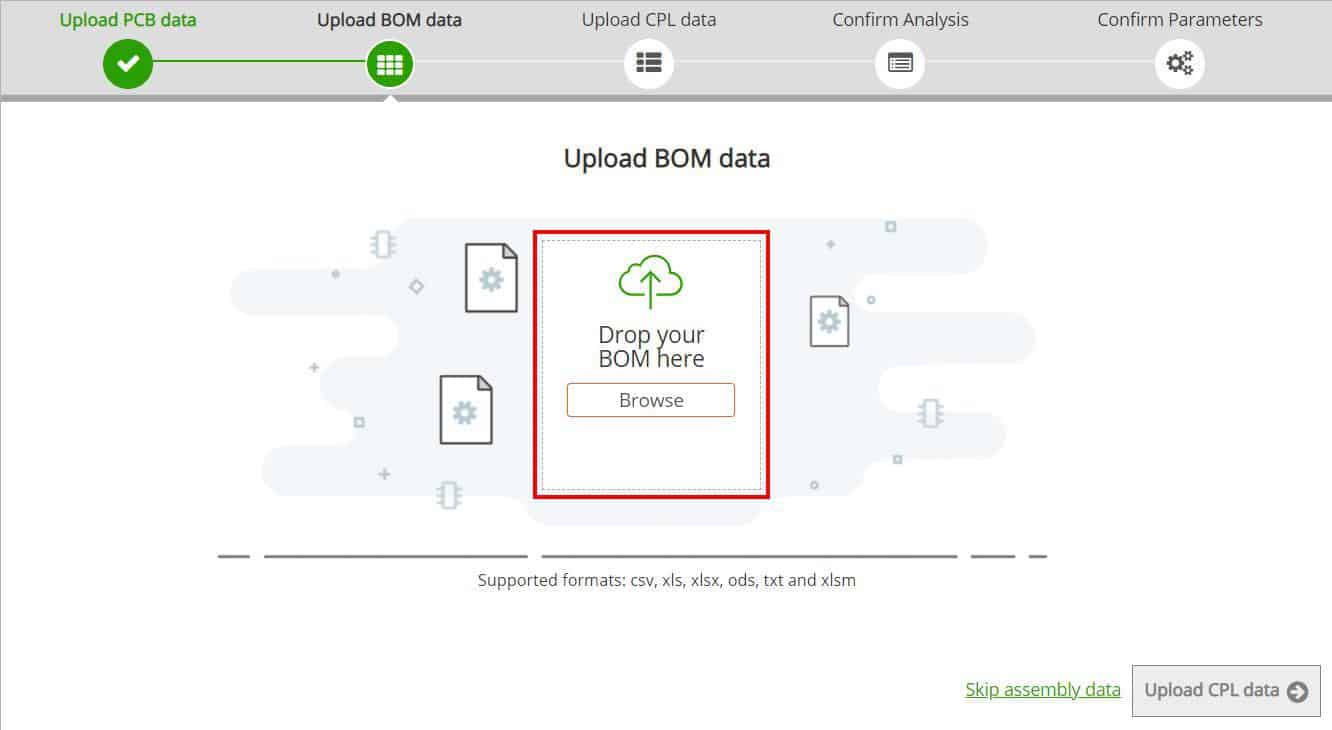
Once the data is uploaded you can then upload your CPL Data file or skip and upload it later.
NOTE
- If you have uploaded your PCB data from a native EAGLE.brd or KiCad file, then the CPL data is already included in this data so you can skip the upload of the CPL.
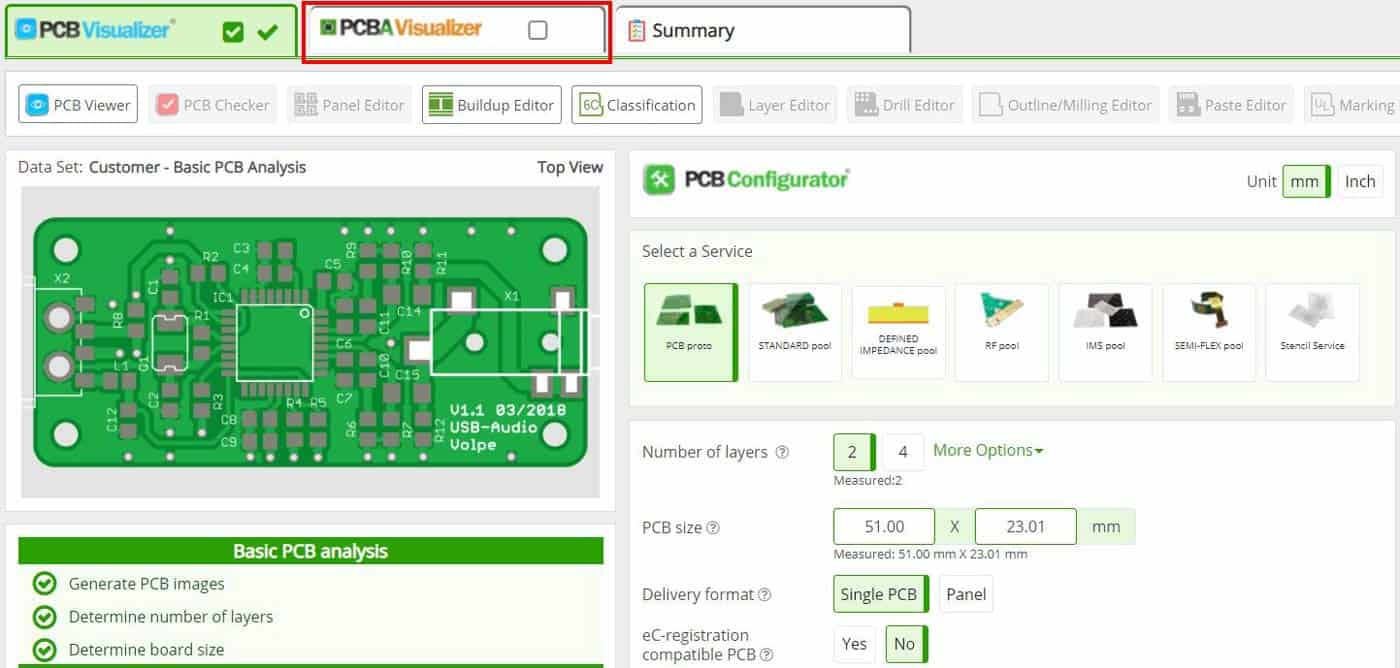
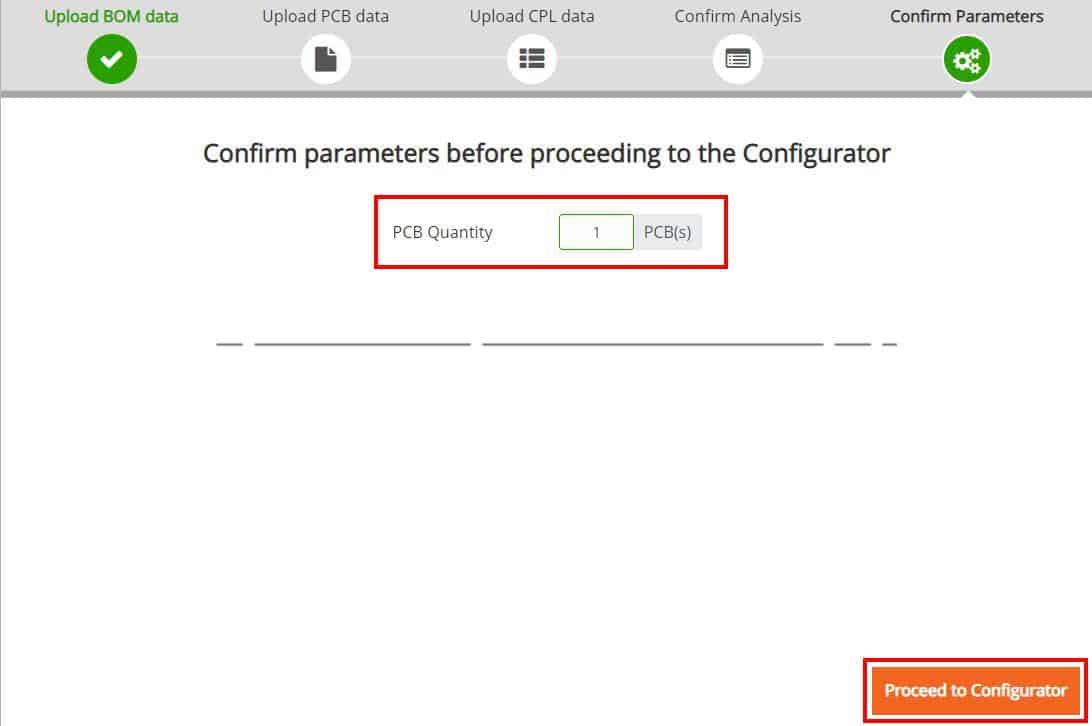
The next window allows you to select either “Full PCB Analysis” or PCB Configurator”.
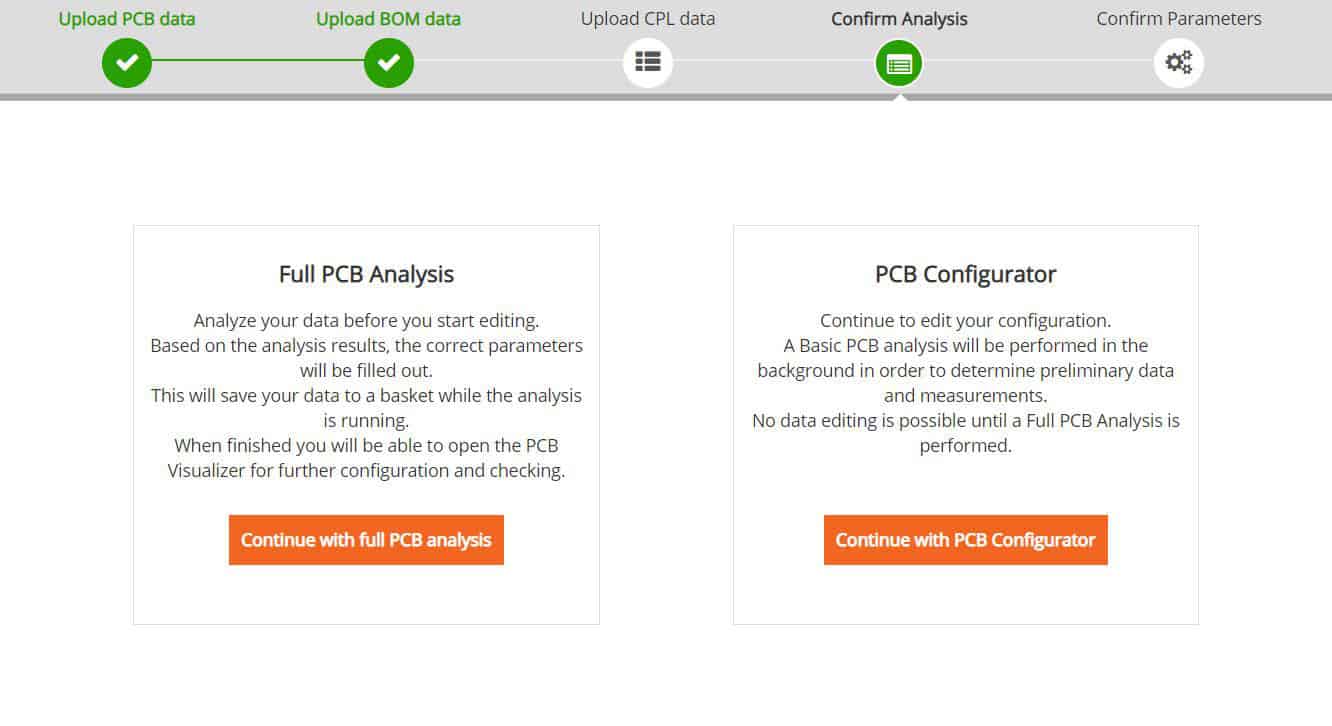
Full PCB Analysis
This requires you to be Signed in to your Eurocircuits account and performs a full DRC check of both your PCB, BOM and CPL (if available) data. It may take a few minutes to complete, depending on the complexity of the data.
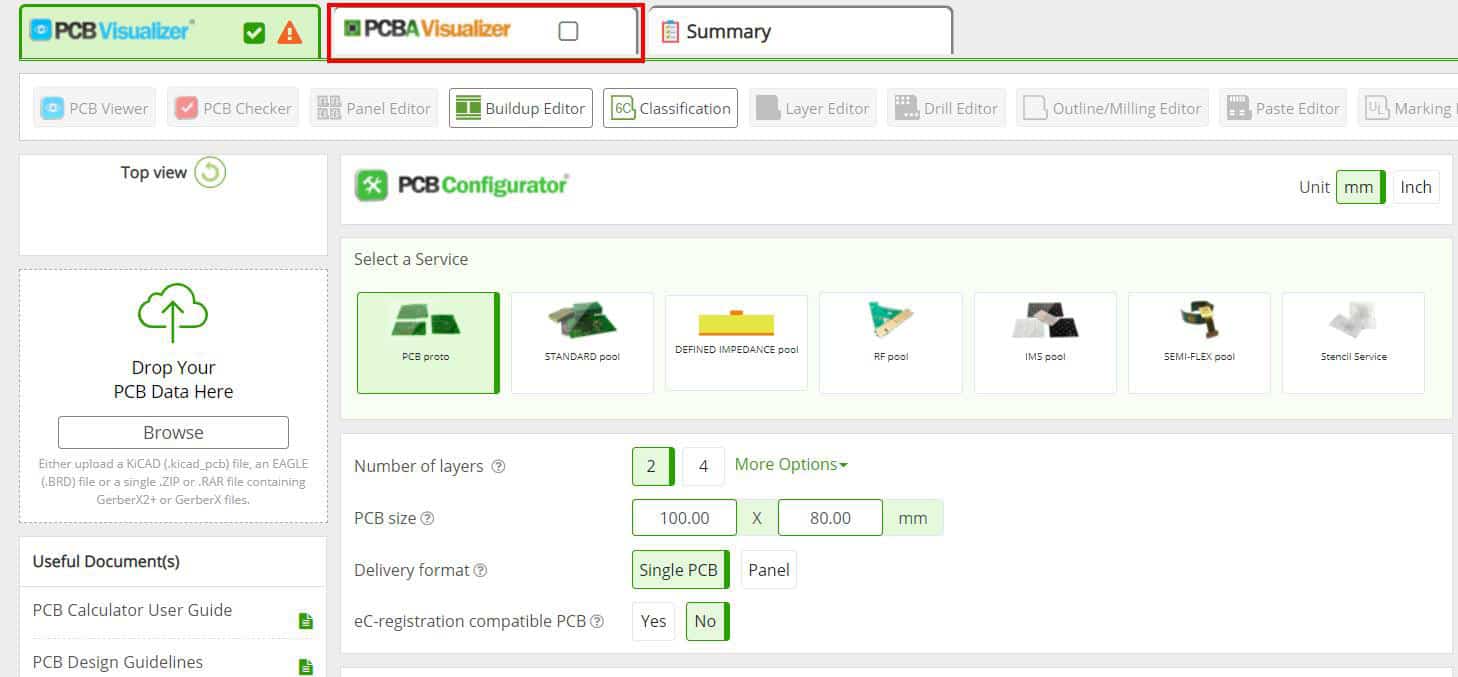
After this is complete the PCB Configurator will open where you will see the price for the bare boards and for the assembly including components and which components are in stock or need to be ordered (On Demand).
You will also be able review the analysis of the layout and see any potential issues and fix them with the Visualizer smart tools.
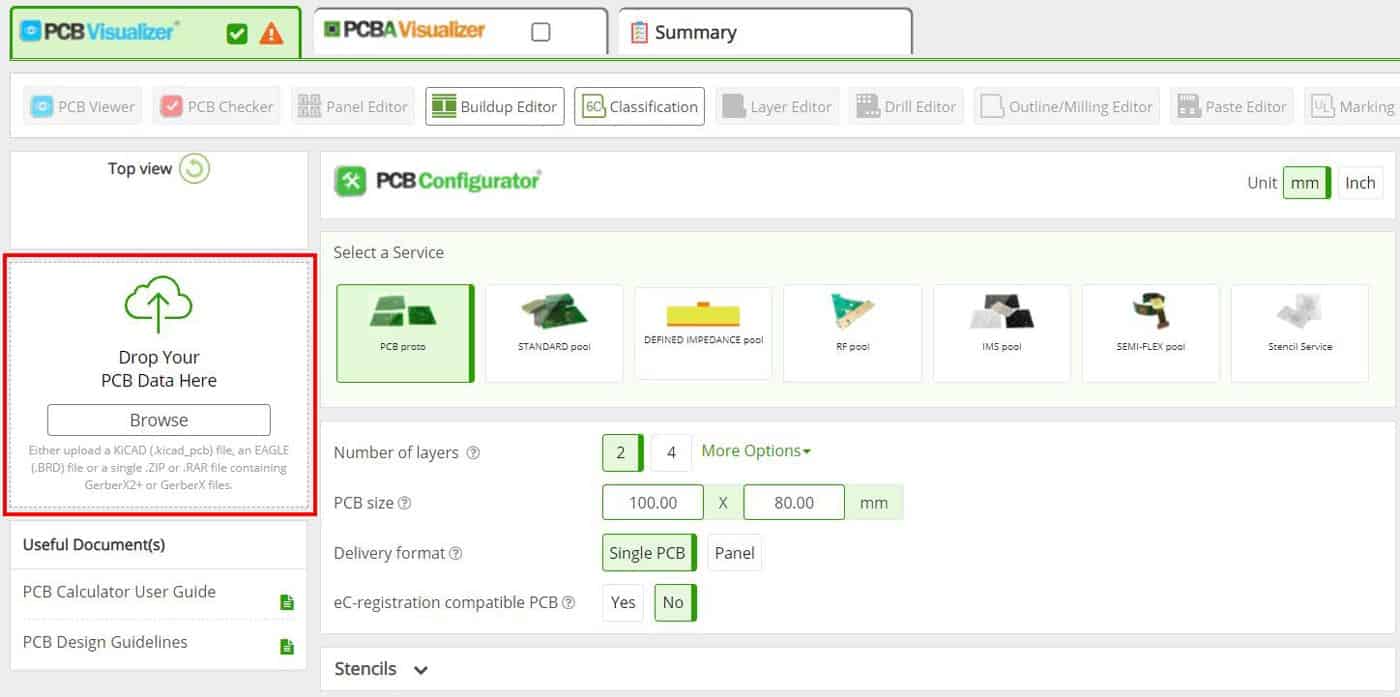
PCB Configurator
This will open the PCB Configurator and provide a graphical representation of your Data without any DRC check. You can also change and select different manufacturing options for the bare board.
Use this if you need a quick price or to see if your data has been output correctly from your CAD system. To check your BOM data (or CPL data) you will need to Sign in to your Eurocircuits account.
Once you have signed in you can then review your BOM data, check component availability, price and change components if necessary.